We can segregate the best practices to be followed into two major categories.
- Designer perspective
- Developer perspective
- Designer perspective:
- First things first, A designer should Have a firm understanding of Functional Specification. To some degree, the Functional Specification may undergo a few minor amendments while the task of Technical Specification is underway. However, it is expected that the Functional Specification has defined all the messages, components and processes that are required for the interface before the commencement of Technical Design.
- Now for flow designing, all the organizations have re-usable common flows (sub flows) as libraries for Auditing and exception handling. But I love to identify other common process across the projects and have independent common flow prepared for that. We can call this as microservice architecture. Explained below with examples.
Example 1:
Let’s say you have few projects (OR same projects across multiple countries) where the final back end is Database and your IIB flows has to make bunch of SQL inserts.
For this we can have a flow created which accepts “SQL inserts” as input from main flow and do a bulk insert at once. This way we can decrease roll out period of similar pattern project from now on.
Example 2:
I worked in project where we use Salesforce as CRM and had many services needed to connect with it where each time there is a call to salesforce for fetching sessionID and then make another call for actual business transaction.
Here we have a scope to make the sessionID call webservice as independent common flow.
- There are new cool features in IIB 10 which helps for better performance and ease of development. Such as:
- Shared libraries Callable flows RestAPI project (generates API from Swagger doc) webUI for Transaction monitoring. MQTT nodes for PUB SUB even without local MQFrom IIB 10.0.0.14, it is possible to use aggregation even without using MQ.Having few standard patterns across organization will lead to ease of reusability of code/modules.
2. Developer perspective:
Let me start with the CPU & Memory costing tasks.
- Message parsing
- Navigating a tree in code
- Copying tree from every node to next node
- Logic in code
- Resource access ( DB/files/HTTP req etc..)
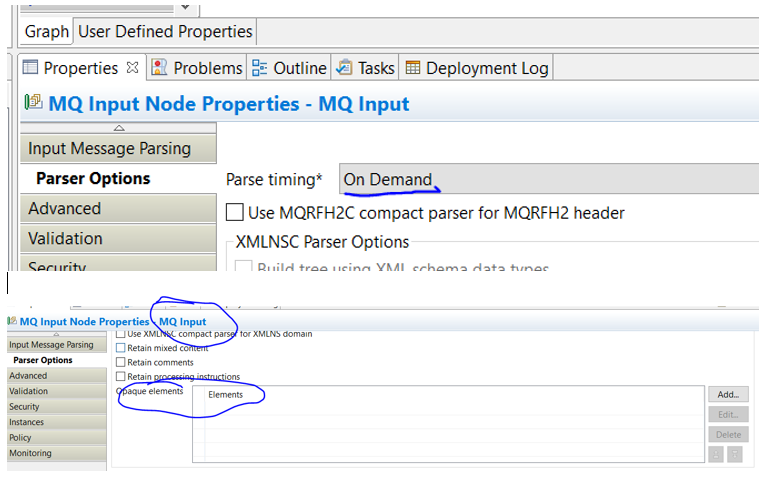
- Reduce memory and CPU utilization by using OnDemand/opaque parsing. Try reducing parsing as much as possible.
- Persistent messages follow 3 commit rule for completion of “unit of work” thus taking more processing time. For un-important messages like “balance inquiry” which has expiry time no need to use persistence.
- ESQL reference variables should be used for navigating message tree.

- Don’t have too many compute nodes in a flow, this helps in reduced message trees being copied.
- Avoid below functions in ESQL code for better performance:
- EVAL
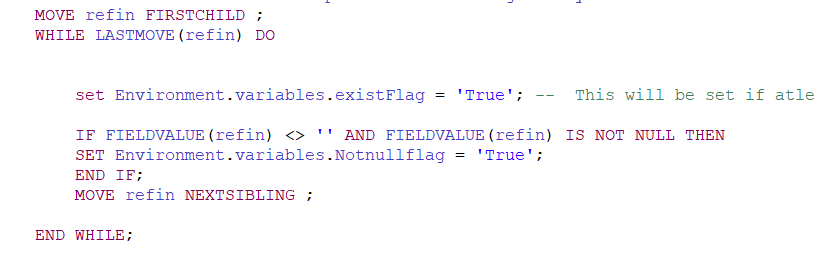
- Cardinality – Try to accomplish the task of looping with “Lastmove” instead.
- Instead of too many “IF ELSE”, good to use “CASE”.
- Have transaction maintained in each and every flow.
- As I said above accessing resource like DB/files etc, can cost us time and CPU, have a well-designed flow thus reducing the access by number of times
- Have a back-out queue configured for all input queues, if not all failed messages may go to dead-letter-queue and difficult to identify each and every service’s message for reprocessing.
- Global cache helps in sharing frequently needed data across all integration servers.
- Have a proper and detailed plan of AVP verification after restart of integration Nodes.
#IIB #IntegrationBus #IBMAppConnect #Integration #ESB #IBMIIB #Middleware #SOA #WSDL #SOAP
